A standard neural network is made up of interconnected neurons in a layered structure that resembles the human brain.

Every neuron has multiple inputs and one output. Lets say our neuron has 2 inputs and 1 output
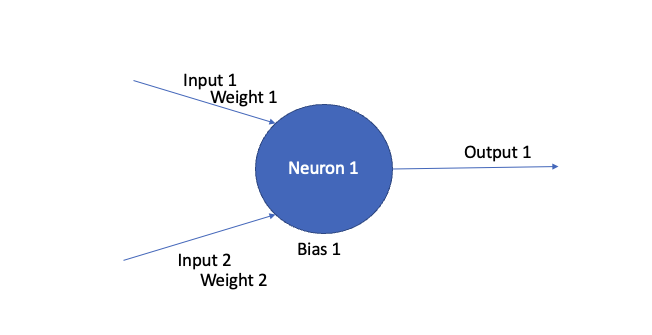
The output formula is
weight 1 X Input 1 + weight 2 X Input 2 + Bias 1 = Output 1
where weight 1 and weight 2 are weights assigned to each input and Bias 1 is the overall bias of this node.
When we create a neural network, it will have multiple neurons stacked in multiple layers.
Let’s say we are trying to solve our Computer vision problem with a standard neural network. Assuming out input data is a grayscale image of 100 X 100 pixels which translates to a matrix of 100 x 100 pixels which is 10,000 pixels or input points
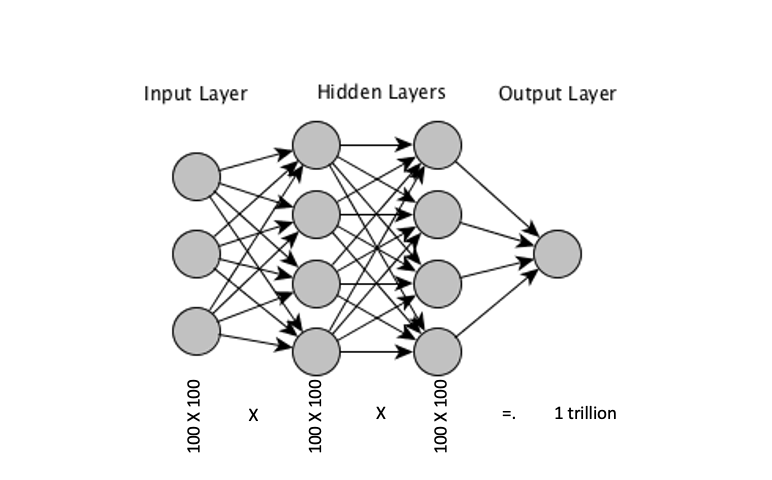
Lets say our 2 layers have 10k neurons as well, which will make the weight/bias matrix to be
10000 x 10000 x 10000 = 1,000,000,000,000 weights (1 trillion weights).
Imagine how much processing / iterations / back propagation would be needed to train the weights for these neurons and with so specifically calculating for each pixel / neuron, it will result the model which is overfitted to the input data, which means on unseen data this model will not work as well.
How CNN solves this
CNN solves this by layering of information. It tries to identify the low level features as eyes, nose, lips on a face, It assumes a low level feature can be present anywhere in the picture. Then it makes up high level feature consisting of low level features to deduce the result.
There are 3 theories in CNN
Low level features are local – Eyes, nose etc are local features which make up bigger features and since they are small, they can be identified using small filters.
Features are translation invariant – They can be present anywhere in the image
High level features are made up of low level features – so if you have 2 eyes, a nose and a mouth, its probably a face.
Lets go over the core elements in CNNs step by step
Filters / Convolutions / feature detector
These are generally small 3×3 matrix which are multiplied (convolved) over the image by going over (sliding over) the image and creating a resulting matrix. It helps detect whether this feature matrix was turned ON by any of the pattern in the image anywhere. So by this we reduce the input size to the next layer.
Pooling
Combines adjacent cells to extract one value. This is also called down sampling and helps us to reduce the number of parameters in our network. It still retains important features because the contour information which is the most important information in the image is not lost with this down sampling. Our brains also work primarily on contours recognition in the image and that is why a face/caricature drawn in a comic book is relatable to a real person.
There is an added benefit to it that if the image is shifted a bit, it does not matter much since we are not looking at exact pixels.
Activation functions
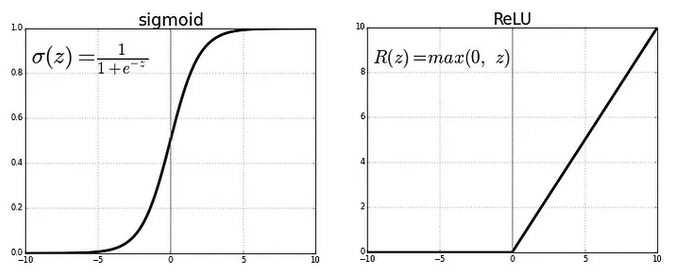
This is a function which is applied to the output of the neuron to denote whether the neuron was activated or not. There are many options in this like Linear, Sigmoid etc. ReLU function is the most used one, It simply marks all values less than 0 to 0, and keep the positive values as is.
Flattening – converts a multi dimension array to a single dimension
Softmax – normalizes the aggregated probability of the result to be feed back into training through back propagation.
Now in our CNN the same 100 x 100 gray scale image is worked on by 2 hidden layers with 100 features each.
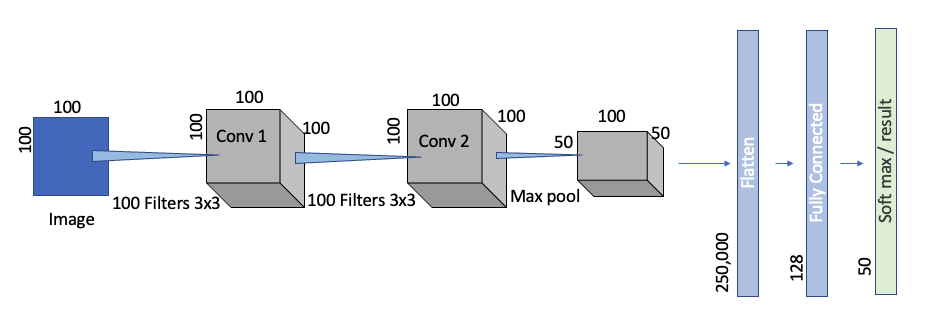
The matrix below shows how many weights we have to track layer by layer. The maximum intersection is between the flattened layer and the fully connected layer.

In this case we just need 32 million weights to be calculated which is 30K times less than the neural network. So if CNN can be trained in 1 day. A Neural Network with lot less accuracy needs 85 years to train. It also gives the other benefits we mentioned
Cheers – Amit Tomar