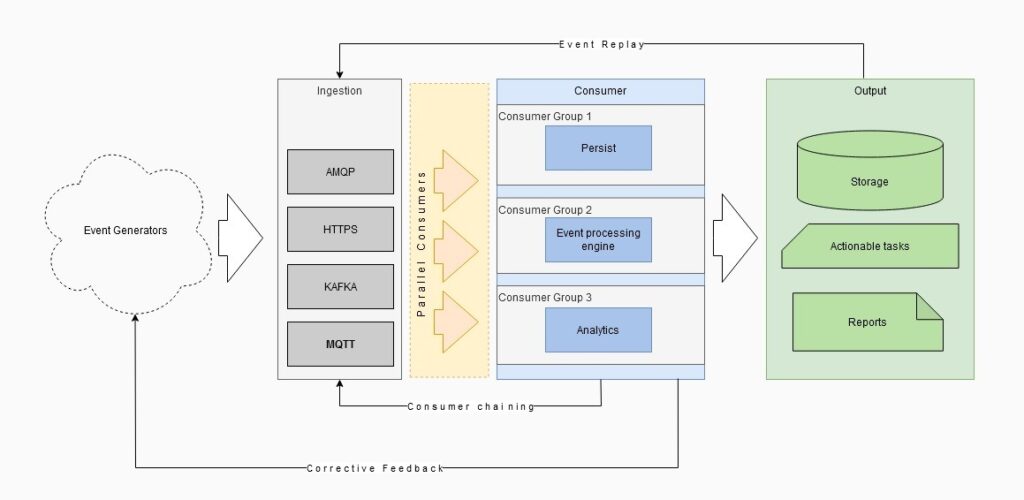
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
It was created by LinkedIn, later open sourced and is maintained by Confluent, Cloudera, IBM, kafka has distributed, resilient and fault tolerant architecture
Topic
A topic is a named stream of data. It carries all events from producers to subscribers. A topic internally treats all data as bytes only. By default it keeps 7 days worth of data which is available to consumer if it wants to query from beginning.
Brokers, Partitions and offsets
A topic can be split in partitions. This encourages distributed nature of scaling. The partitions are hosted on servers (called Brokers). Each Broker can have several partitions from several topics hosted on it.
The incoming data on a topic is split on split on the partitions. There are multiple split strategies available for distributing the data across partitions.
If a message does not have a key value structure, the producers tend to send the message in a round robin fashion. It does not do round robin per message, but on a per batch basis. A batch of messages is on a time window and a max size of the batch.
If the message does have a key and value structure, the partition id is decided by the murmur2 hash of the key. This ensures the same key lands on the same partition.
The messages are stored on the topic in the sequence they arrive from the producer. The order of messages is guaranteed on a partition, but not across partitions.
Let’s say 2 sensors are reporting the temperature, and the data is getting sent to separate partitions. So individually the data for each sensor will be time ordered. A consumer when reading data from one partition will get the data in the right sequence for the sensor.
Producers and Consumers
A producer sends the message to a topic. Since kafka takes data only in bytes, we have to define the key and value serializers and deserializers. Common formats of data which is sent over Kafka is Strings, jsons, Numbers, and optimized jsons like Avro, Protobuf.
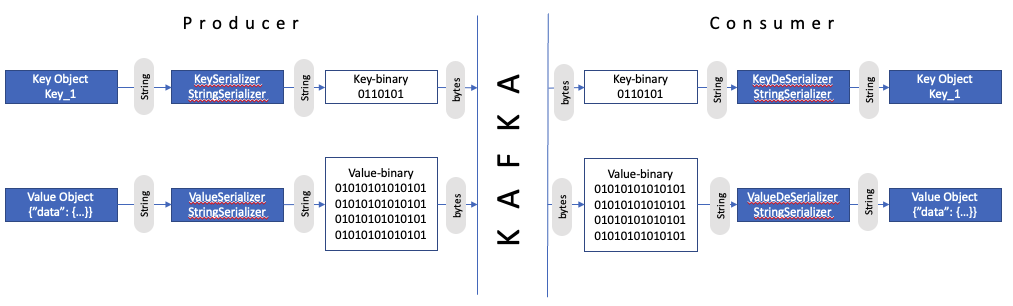
Consumers read data from a topic using a pull model. One consumer can be attached to one or multiple partitions, also one consumer can ready from multiple topics. A consumer group is a group of multiple consumers reading from the same topic but different partitions. A consumer group is a group of consumers doing the same job with the data.
Multiple consumers in same group will share the load from partitions and one consumer can read from multiple partitions.
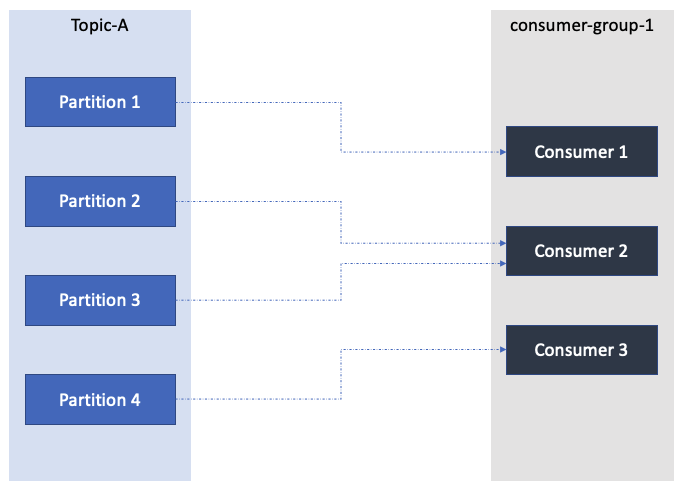
Multiple consumers in the same consumer group cannot read from the same partition. If there are more consumers then partitions then some consumers will remain free. They keep track of the read data using offsets so as to not process the same data twice.
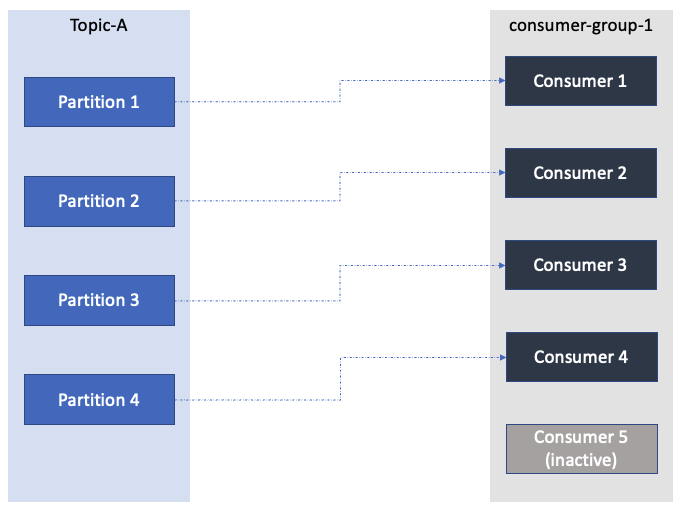
But different consumer groups can read from same topic same partitions. Example if we have log data coming in, we can have a sink consumer group which will push data to sink, another group which will look for errors in the logs and another one which will look for security/performance issues
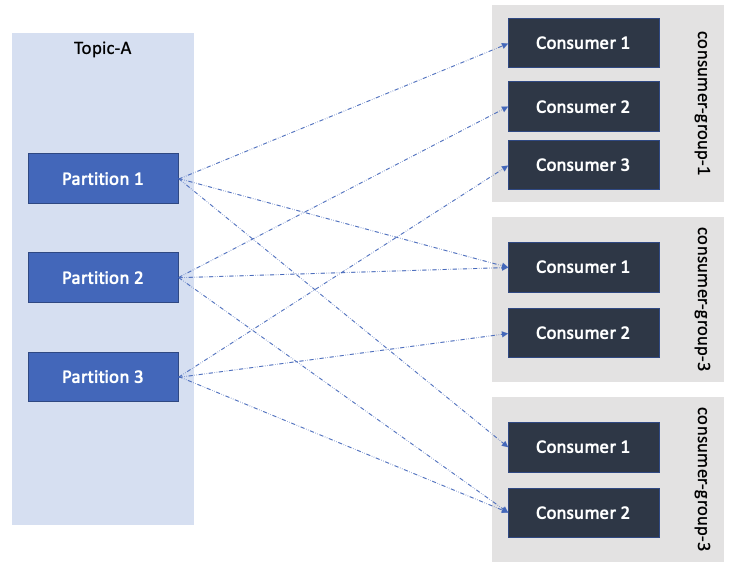
Each consumer group keeps a track of how many messages have been read. In above example if one of the consumer groups needs a restart, it will use its own offsets commited earlier to read from that point onwards
Semantics for Offsets
The offsets are written periodically after each batch consumption. Kafka consumes messages same was as it produces, basically batches based on time window and size limit whatever reaches first.
The message processing commits are done in 3 ways
At least once – Offsets get committed after the processing. The message may thus be processed again if the offset is not committed back in batch processing. Ensure duplicate processing does not negatively impact the system.
At most once – Offsets get committed as soon as they are picked up before the processing. So if any problem in processing, the message is lost.
Exactly once – Possible with Kafka transactional API (work flows)
Producer code example
String bootstrapServer = "127.0.0.1:9092"
// create Producer properties
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServer);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// create the producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// create a producer record
String topic = "testTopicName";
String key = "key " + Integer.toString(i);
String value = "value " + Integer.toString(i);
ProducerRecord<String, String> producerRecord = new ProducerRecord<>
(topic, key, value);
// send data
producer.send(producerRecord);
// flush data
producer.flush();
// flush and close producer
producer.close();Consumer Code example
String bootstrapServers = "127.0.0.1:9092";
String groupId = "myConsumerGroup";
String topic = "testTopicName";
// create consumer configs
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// create consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// get a reference to the current thread
final Thread mainThread = Thread.currentThread();
// subscribe consumer to our topic(s)
consumer.subscribe(Arrays.asList(topic));
// poll for new data
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
log.info("Record: " + record.key() + " => " + record.value());
}
}
// For graceful exits we need to add shutdown hooks above
// and add consumer.close(); in it after this.
Cheers – Amit Tomar