

When the transformer model came in the “Attention is all you need” paper, it changed the way NLP tasks were handled. I explained it in my previous post Transformer model
In 2021 there was another paper “An image is worth 16×16 words” to attempt doing computer vision tasks using the transformer model.
The model ignores the traditional approach of filters used for CNNs and models the input image in patches of 16×16. It also uses the NLP approach of context capture using positional encoding to provide reference of different patches coming in as to where they are in the original image
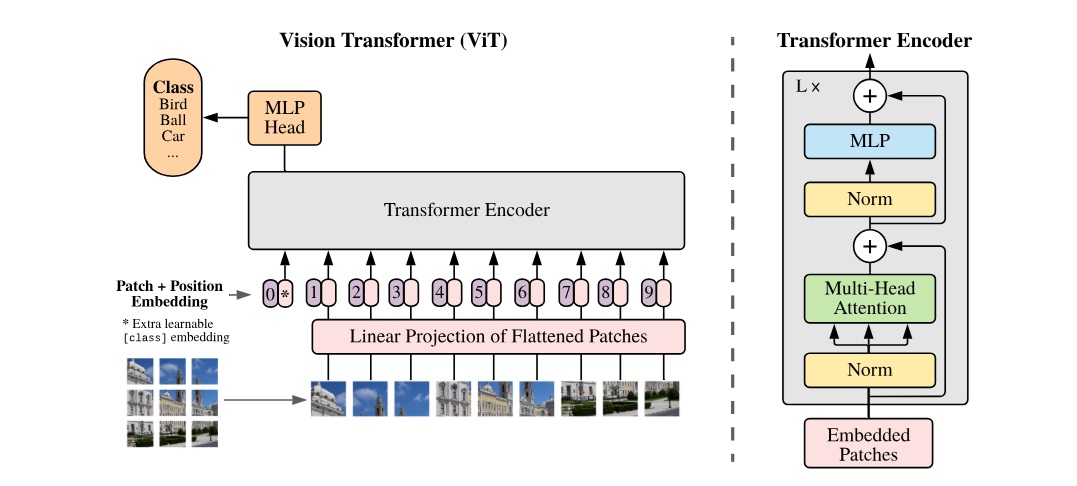
Let’s take an input image of 256×256 with 3 channels.
It gets divided into patches of 16×16, so we have 16 rows and 16 columns resulting in 256 patches.
Every patch has 3 channels so the size of each patch is 16x16x3 = 768
Divide the input image into patches
patches = tf.image.extract_patches(
images=x,
sizes=[1, 16, 16, 1],
strides=[1, 16, 16, 1],
rates=[1, 1, 1, 1],
padding='VALID')
Reshape patches to flatten the 3 layers to get a 768 tensor
patches = tf.reshape(patches, (tf.shape(patches)[0], 256, patches.shape[-1]))
Now you have 256 inputs (pink ovals) with size of 768 each.
create the embeddings for positional reference
positional_embedding = Embedding(256, 768 )
embedding_input = tf.range(start = 0, limit = 256, delta = 1 ) // 1 ... 256
pos_embedding = positional_embedding(embedding_input)
This is same shape as the linear projection of patches, the pos_embeddings are the purple ovals in the image marked 1,2,3.. etc.
Now we join the patches and the embeddings
linear_projection = Dense(768)
output = linear_projection(patches) + pos_embedding
This all above can be written in a class as
class PatchCreator(Layer):
def __init__(self):
super(PatchCreator, self).__init__(name = 'patch_creator')
self.linear_projection = Dense(768)
self.positional_embedding = Embedding(256, 768 )
def call(self, input_images):
patches = tf.image.extract_patches(
images=input_images,
sizes=[1, 16,16, 1],
strides=[1, 16,16, 1],
rates=[1, 1, 1, 1],
padding='VALID')
patches = tf.reshape(patches, (tf.shape(patches)[0], 256, patches.shape[-1]))
embedding_input = tf.range(start = 0, limit = 256, delta = 1 )
pos_embedding = positional_embedding(embedding_input)
output = self.linear_projection(patches) + pos_embedding
return output
Now our input is ready to go in the gray box (Transformer encoder)
The transformer encoder has multiple layers
//First yellow Norm layer
layer_norm_1 = LayerNormalization()
//Green Multi-Head attention
multi_head_att = MultiHeadAttention(N_HEADS, 768 )
//Second yellow Norm layer
layer_norm_2 = LayerNormalization()
The Blue MLP ( multi-layer perceptron) is made of 2 dense layers with gelu non-linearity
dense_1 = Dense(768, activation = tf.nn.gelu)
dense_2 = Dense(768, activation = tf.nn.gelu)
Putting the calls in sequence for transformer encoder:
//First Yellow box
x_1 = self.layer_norm_1(inputPatches)
//Green box
// the inputs (Query, Value, Key) values going into the multi-head attention
// We will keep Q & V same and K is optional
x_1 = self.multi_head_att(x_1, x_1)
// First White + circle
x_1 = Add()([x_1, inputPatches])
//Second Yellow box
x_2 = self.layer_norm_2(x_1)
//Blue MLP box contains 2 dense layers
x_2 = self.dense_1(x_2)
x_2 = self.dense_2(x_2)
// Second White + circle
output = Add()([x_2, x_1])
This all above can be written in a class as
class TransformerEncoder(Layer):
def __init__(self, HEAD_COUNT):
super(TransformerEncoder, self).__init__(name = 'transformer_encoder')
self.layer_norm_1 = LayerNormalization()
self.multi_head_att = MultiHeadAttention(HEAD_COUNT, 768 )
self.layer_norm_2 = LayerNormalization()
self.dense_1 = Dense(768, activation = tf.nn.gelu)
self.dense_2 = Dense(768, activation = tf.nn.gelu)
def call(self, inputPatches):
x_1 = self.layer_norm_1(inputPatches)
x_1 = self.multi_head_att(x_1, x_1)
x_1 = Add()([x_1, inputPatches])
x_2 = self.layer_norm_2(x_1)
x_2 = self.dense_1(x_2)
x_2 = self.dense_2(x_2)
output = Add()([x_2, x_1])
return output
Now joining the Patch creator and the Transformer encoder into a Vision Transformer model
Start with PatchCreator
patch_creator = PatchCreator()
we need L Transformer encoders
transformer_encoders = [TransformerEncoder(HEAD_COUNT) for _ in range(LAYER_COUNT)]
The final orange MLP head which contains 2 dense layers with gelu non-linearity
mlp_1 = Dense(DENSE_COUNT, tf.nn.gelu)
mlp_2 = Dense(DENSE_COUNT, tf.nn.gelu)
The last classification step to generate our classes
fc_classifier = Dense(CLASSES_COUNT, activation = 'softmax')
Calling the layers in order
x = patch_creator(input)
for i in range(self.LAYER_COUNT):
x = transformer_encoders[i](x)
x = Flatten()(x)
//MLP head
x = mlp_1(x)
x = mlp_2(x)
//final classification
x = fc_classifier(x)
This all above can be written in a class as
class VisionTransformer(Model):
def __init__(self, HEAD_COUNT, LAYER_COUNT, DENSE_COUNT, CLASSES_COUNT):
super(VisionTransformer, self).__init__(name = 'vision_transformer')
self.LAYER_COUNT = LAYER_COUNT
self.patch_encoder = PatchEncoder()
self.transformer_encoders = [TransformerEncoder(HEAD_COUNT) for _ in range(LAYER_COUNT)]
self.mlp_1 = Dense(DENSE_COUNT, tf.nn.gelu)
self.mlp_2 = Dense(DENSE_COUNT, tf.nn.gelu)
self.fc_classifier = Dense(CLASSES_COUNT, activation = 'softmax')
def call(self, input, training = True):
x = self.patch_encoder(input)
for i in range(self.LAYER_COUNT):
x = self.transformer_encoders[i](x)
x = Flatten()(x)
x = self.mlp_1(x)
x = self.mlp_2(x)
x = self.fc_classifier(x)
return x
Now we can instantiate the vision transformer as
vit = VisionTransformer(
HEAD_COUNT = 4, LAYER_COUNT = 2,
DENSE_COUNT = 128, CLASSES_COUNT = 3)
And training of the model can be done like
history = vit.fit( training_dataset, validation_dataset, epochs = 10, verbose = 1)
Some notes about the using the transformer model usage in computer vision
As described in paper, the accuracy of this model is better than ResNet only when the training dataset is significantly large.
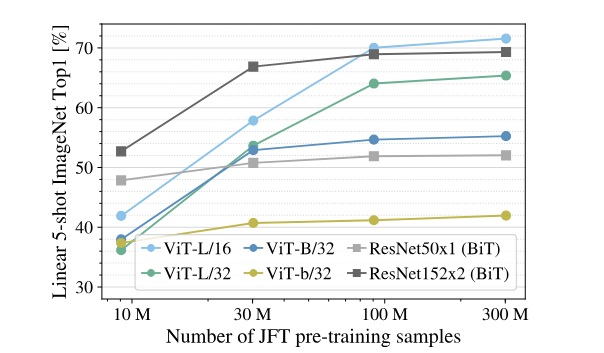
This is because to generate context from images, this model needs good amount of data since the images gets divided into patches. A CNN based on ResNet gains that accuracy faster because it looks at the whole image.
In case of large training sets the accuracy of this transformer model exceeds the accuracy for ResNet.
-Cheers Amit Tomar


