

I am starting a series on text processing using deep learning methodologies. I will take you through the principles deployed in converting textual information to numerical formats, to the processing using Recurrent Neural networks, the transformer model and its use in GPT and BERT models.
There are couple of considerations when processing text and translating it into vectors. We have to understand the context of the word, just “Take Out” has couple of meanings depending on context.
To understand context, we need to preserve some level of work ordering, and send this work ordering in a way that it is not lost by the time the processing is in last part of sentence.
Then there is the vocabulary list. Too short and we do not understand anything, too big will use up all the processing.
Tokenization
Tokenization is a way of separating a piece of text into smaller units called tokens. Here, tokens can be either words, characters, or subwords. Hence, tokenization can be broadly classified into following types – word, character, and subword (n-gram characters) tokenization.
Imagine you are processing following text – “Get smarter everyday.”
Character tokenization
You will have a vocabulary of all characters in a order, like
[1:”a”, 2:”b”, 3:”c”, 4:”d” .. 26:”z”, 27:” “, 28:”.”]
The above sentence will then translate to
[7,5,20,27,19,13,..28]
where every word is replaced by its corresponding number in vocabulary.
This will keep vocabulary small, but the context of word is lost.
Word Tokenization
In this case the vocabulary consist of all commonly used words and can be 10k long
So if the vocabulary is
[1:”get”, 2:”set”, 3:”smart”, 4:”smarter”, 5:”everyday”]
the vector translation will be
[1, 4, 5]
Subword tokenization
This is a middle ground and also has a benefit to work around spelling mistakes in input as at-least part of work is considered
If we have the vocabulary as
[1:”get”, 2:”set”, 3:”er”, 4:”day”, 5:”every”, 6:”smart”, 7:”how”, 8:”to”]
The the vector representation will be
[1,6,3,5,4]
Next step is to pass this to the model, we cannot pass this vector as is to model, since it will learn more of a sequence of numbers rather than word, its meaning, its context.
Lets say our example sentence is [Try and try again till you succeed.]
Bag of words
In this model, a text (such as a sentence or a document) is represented as the multi-set of its words, disregarding grammar and even word order but keeping multiplicity.
So if we go with a vocabulary [“a”, “apple”, “again”, “and”, “you”, “try”, “success”, succeed”, “till”]
The bag of words vector will be [0, 0, 1, 1, 1, 2, 0, 1]
It keeps the order what is coming from the vocabulary, so its length is same as vocabulary and the numerical values represent the count that word occurred in the sentence.
One Hot notation
This method tries to disrupt the sequence model of using numbers where there is a risk of learing relationship betweek smaller and larger numbers.
For each word in the sentence, it creates a vector of all nulls, the same size as vocabulary, but for the position where this word matches the vocabulary
So if we go with a vocabulary
[“a”, “apple”, “again”, “and”, “you”, “try”, “success”, succeed”, “till”]
[Try and try again till you succeed.]
[0] [0] [0] [0] [0] [0] [0]
[0] [0] [0] [0] [0] [0] [0]
[0] [0] [0] [1] [0] [0] [0]
[0] [1] [0] [0] [0] [0] [0]
[0] [0] [0] [0] [0] [1] [0]
[1] [0] [1] [0] [0] [0] [0]
[0] [0] [0] [0] [0] [0] [0]
[0] [0] [0] [0] [0] [0] [1]
[0] [0] [0] [0] [1] [0] [0]Term frequency – inverse document frequency
It can be defined as the calculation of how relevant a word in a series is to a text. The meaning increases proportionally to the number of times in the text a word appears but is compensated by the word frequency in the text
Term frequency is the number of times a word appears in sentence vs the total number of words in the sentence
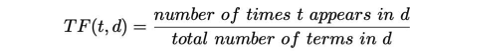
Inverse document frequency is a measure of how much information the word provides, i.e., if it is common or rare across all documents
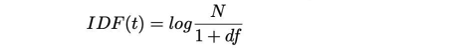
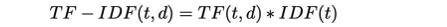
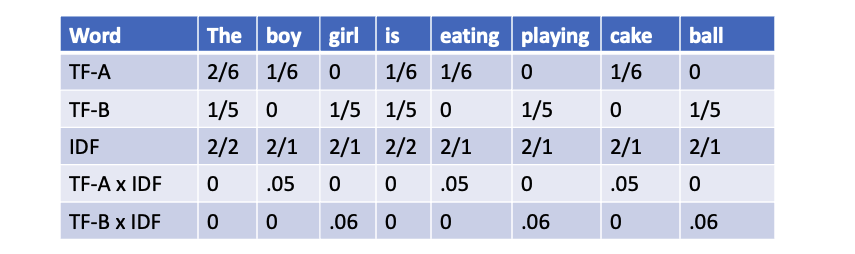
Sentence 1: The boy is eating the Cake.
Sentence 2: The girl is playing ball.
Putting it all together
from sklearn.naive_bayes import MultinominalNB
//we are passing the messages in tf-idf format and the label classified it as positinve or negative
sentiment_model = MultinominalNB.fit(messages_tfidf, messages[‘label’])
//predict the sentiment in my_message
sentiment_model.predict(my_message);Next session we will dive into Recurrent Neural Networks and the attention model.
Cheers – Amit Tomar


