Captcha is created by a computer, and now the computer itself is advanced enough to break its own doing. Deep learning algorithms have come a long way in the last couple of years. You take pre-classified data and break in into 2 or 3 parts, use the first part for training and the remaining parts for validations
The underlying principle for Deep learning is mostly same whether you are working data or images. In Images you have to add convolution layer and some extra processing to ignore details but still extract the main content.
Main code now is written by developer in Data Cleaning. It takes time to prepare and organize the data so proper training can happen.
Once we have the model, we run it against the validation data and come up with a confusion matrix
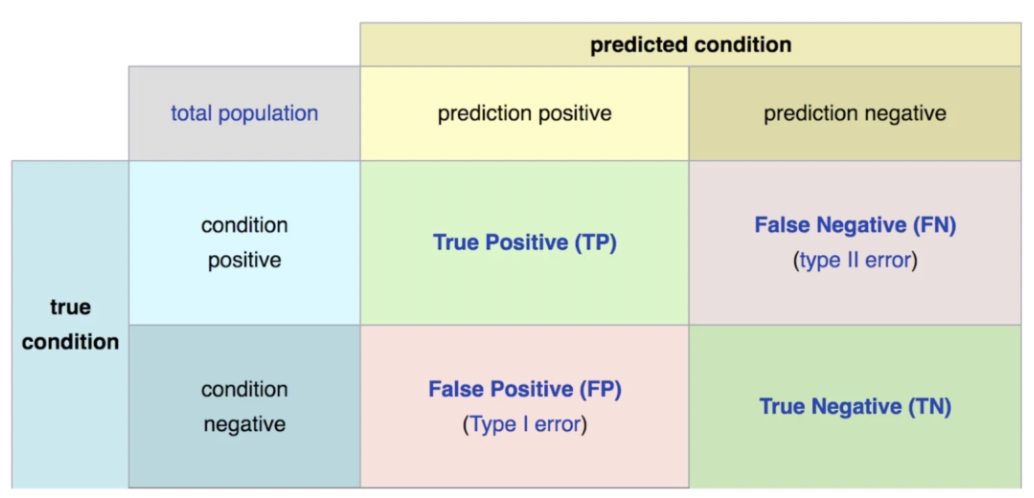
The goal generally is to increase the True Positive and True Negative and reduce the false predictions, but depending on business case the goal may be different, for eg. while predicting a medical condition, you may want to err on side of caution and False Positives should be OK, and main goal should be to reduce only False Negatives (Telling a patient he is OK when there really a problem)
Captcha detection
Read the images and prepare what we are going to parse
import os
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
from collections import Counter
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# Path to the data directory
data_dir = Path("./captcha_images/")
# Get list of all the images
images = sorted(list(map(str, list(data_dir.glob("*.png")))))
labels = [img.split(os.path.sep)[-1].split(".png")[0] for img in images]
characters = set(char for label in labels for char in label)
print("Number of images found: ", len(images))
print("Number of labels found: ", len(labels))
print("Number of unique characters: ", len(characters))
print("Characters present: ", characters)
# Desired image dimensions
img_width = 200
img_height = 50
# Maximum length of any captcha in the dataset
max_length = max([len(label) for label in labels])
# Mapping characters to integers
char_to_num = layers.StringLookup(
vocabulary=list(characters), mask_token=None
)
# Mapping integers back to original characters
num_to_char = layers.StringLookup(
vocabulary=char_to_num.get_vocabulary(), mask_token=None, invert=True
) Split the data into training and validation
# This splits the data in training and validation sets.
# There is a sklearn dataframe library which can also do same thing
# https://scikit-learn.org/stable/
# from sklearn.model_selection import train_test_split
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=101)
def split_data(images, labels, train_size=0.9, shuffle=True):
# 1. Get the total size of the dataset
size = len(images)
# 2. Make an indices array and shuffle it, if required
indices = np.arange(size)
if shuffle:
np.random.shuffle(indices)
# 3. Get the size of training samples
train_samples = int(size * train_size)
# 4. Split data into training and validation sets
x_train, y_train = images[indices[:train_samples]], labels[indices[:train_samples]]
x_valid, y_valid = images[indices[train_samples:]], labels[indices[train_samples:]]
return x_train, x_valid, y_train, y_valid
# Splitting data into training and validation sets
x_train, x_valid, y_train, y_valid = split_data(np.array(images), np.array(labels))
# x is the image and y is the label. .convert to dataset to be processed, and display some of the test data
def encode_single_sample(img_path, label):
# 1. Read image
img = tf.io.read_file(img_path)
# 2. Convert to grayscale
img = tf.io.decode_png(img, channels=1)
# 3. Convert to float32 in [0, 1] range
img = tf.image.convert_image_dtype(img, tf.float32)
# 4. Resize to the desired size
img = tf.image.resize(img, [img_height, img_width])
# 5. Transpose the image because we want the time
# dimension to correspond to the width of the image.
img = tf.transpose(img, perm=[1, 0, 2])
# 6. Map the characters in label to numbers
label = char_to_num(tf.strings.unicode_split(label, input_encoding="UTF-8"))
# 7. Return a dict as our model is expecting two inputs
return {"image": img, "label": label}
# Batch size for training and validation
batch_size = 16
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = (
train_dataset.map(
encode_single_sample, num_parallel_calls=tf.data.AUTOTUNE
)
.batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
validation_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid))
validation_dataset = (
validation_dataset.map(
encode_single_sample, num_parallel_calls=tf.data.AUTOTUNE
)
.batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# Show 16 images and their labels in training batch
_, ax = plt.subplots(4, 4, figsize=(10, 5))
for batch in train_dataset.take(1):
images = batch["image"]
labels = batch["label"]
for i in range(16):
img = (images[i] * 255).numpy().astype("uint8")
label = tf.strings.reduce_join(num_to_char(labels[i])).numpy().decode("utf-8")
ax[i // 4, i % 4].imshow(img[:, :, 0].T, cmap="gray")
ax[i // 4, i % 4].set_title(label)
ax[i // 4, i % 4].axis("off")
plt.showTraining the model
########
# till now we have got the images and split them in 2 datasets
########
class CTCLayer(layers.Layer):
def __init__(self, name=None):
super().__init__(name=name)
self.loss_fn = keras.backend.ctc_batch_cost
def call(self, y_true, y_pred):
# Compute the training-time loss value and add it
# to the layer using `self.add_loss()`.
batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64")
input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64")
label_length = tf.cast(tf.shape(y_true)[1], dtype="int64")
input_length = input_length * tf.ones(shape=(batch_len, 1), dtype="int64")
label_length = label_length * tf.ones(shape=(batch_len, 1), dtype="int64")
loss = self.loss_fn(y_true, y_pred, input_length, label_length)
self.add_loss(loss)
# At test time, just return the computed predictions
return y_pred
# This is our deep learning model.
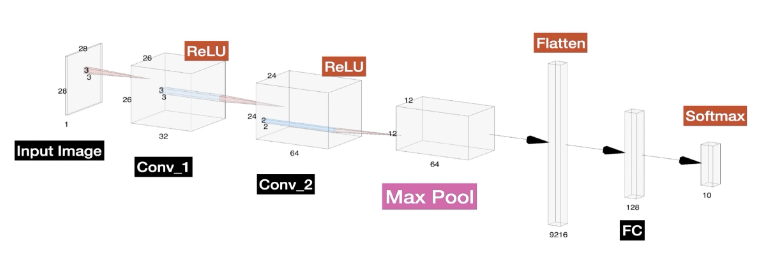
# 2 convolution layers, followed by flattening, fully connected and output
def build_model():
# Inputs to the model
input_img = layers.Input(
shape=(img_width, img_height, 1), name="image", dtype="float32"
)
labels = layers.Input(name="label", shape=(None,), dtype="float32")
# First conv block
x = layers.Conv2D(
32,
(3, 3),
activation="relu",
kernel_initializer="he_normal",
padding="same",
name="Conv1",
)(input_img)
x = layers.MaxPooling2D((2, 2), name="pool1")(x)
# Second conv block
x = layers.Conv2D(
64,
(3, 3),
activation="relu",
kernel_initializer="he_normal",
padding="same",
name="Conv2",
)(x)
x = layers.MaxPooling2D((2, 2), name="pool2")(x)
# We have used two max pool with pool size and strides 2.
# Hence, downsampled feature maps are 4x smaller. The number of
# filters in the last layer is 64. Reshape accordingly before
# passing the output to the RNN part of the model
new_shape = ((img_width // 4), (img_height // 4) * 64)
x = layers.Reshape(target_shape=new_shape, name="reshape")(x)
x = layers.Dense(64, activation="relu", name="dense1")(x)
x = layers.Dropout(0.2)(x)
# RNNs
x = layers.Bidirectional(layers.LSTM(128, return_sequences=True, dropout=0.25))(x)
x = layers.Bidirectional(layers.LSTM(64, return_sequences=True, dropout=0.25))(x)
# Output layer
x = layers.Dense(
len(char_to_num.get_vocabulary()) + 1, activation="softmax", name="dense2"
)(x)
# Add CTC layer for calculating CTC loss at each step
output = CTCLayer(name="ctc_loss")(labels, x)
# Define the model
model = keras.models.Model(
inputs=[input_img, labels], outputs=output, name="ocr_model_v1"
)
# Optimizer
opt = keras.optimizers.Adam()
# Compile the model and return
model.compile(optimizer=opt)
return model
# Get the model
model = build_model()
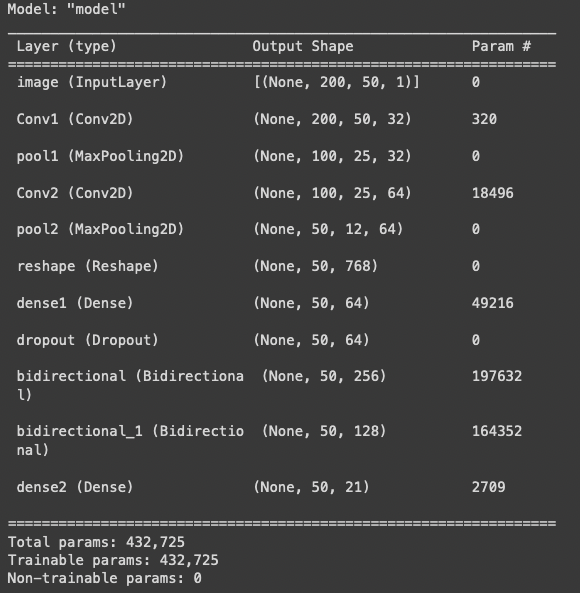
model.summary()
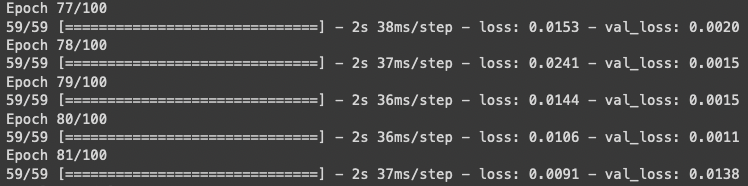
epochs = 100
early_stopping_patience = 10
# Add early stopping to avoid over training on specific dataset.
early_stopping = keras.callbacks.EarlyStopping(
monitor="val_loss", patience=early_stopping_patience, restore_best_weights=True
)
# Now the magic of Learning
# Train the model
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=epochs,
callbacks=[early_stopping],
)
# Get the prediction model by extracting layers till the output layer
# This is the main output of this whole exercise
prediction_model = keras.models.Model(
model.get_layer(name="image").input, model.get_layer(name="dense2").output
)
prediction_model.summary(You have the model, Lets try out how it works on the validation data
# A utility function read the text from the predection.
# This returns the text which was extracted from captcha
def decode_batch_predictions(pred):
input_len = np.ones(pred.shape[0]) * pred.shape[1]
# Use greedy search. For complex tasks, you can use beam search
results = keras.backend.ctc_decode(pred, input_length=input_len, greedy=True)[0][0][
:, :max_length
]
# Iterate over the results and get back the text
output_text = []
for res in results:
res = tf.strings.reduce_join(num_to_char(res)).numpy().decode("utf-8")
output_text.append(res)
return output_text
# Let's check results on some validation samples
# This was built from validation data using the Split we did earlier
for batch in validation_dataset.take(1):
batch_images = batch["image"]
batch_labels = batch["label"]
# Take the trained model and run it on the validation images
preds = prediction_model.predict(batch_images)
pred_texts = decode_batch_predictions(preds)
# Now its all just pretty plotting the results.
orig_texts = []
for label in batch_labels:
label = tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
orig_texts.append(label)
_, ax = plt.subplots(4, 4, figsize=(15, 5))
for i in range(len(pred_texts)):
img = (batch_images[i, :, :, 0] * 255).numpy().astype(np.uint8)
img = img.T
title = f"Prediction: {pred_texts[i]}"
ax[i // 4, i % 4].imshow(img, cmap="gray")
ax[i // 4, i % 4].set_title(title)
ax[i // 4, i % 4].axis("off")
plt.show() The output
Some of the training data

Model in training
Model is finishing training, see the loss (or some people call it cost) has reduced, so early stopping is kicking in. We asked it to go to 100 epochs, but it stops at 81.
Model.. so fancy
And this finally is our attempt to test our model on validation data. It seems to have predicted it all correctly. May be it was all just a slight of hand, or was it actual ML.

Cheers – Amit Tomar