

Apache Spark is a powerful aggregation engine which allows computations over very large datasets with minimal coding. It optimizes the job execution using Directed Acyclic Graph (DAG) which gives it better performance than MapReduce. Spark prepares the execution plan over the cluster managed by YARN, Mesos or any other cluster management frameworks. Its in-memory data engine means that it can perform tasks up to one hundred times faster than MapReduce in certain situations, particularly when compared with multi-stage jobs that require the writing of state back out to disk between stages
Spark hides the complexity of MapReduce by providing Scala APIs for RDD and SparkSQL. A Resilient Distributed Dataset (RDD), is a programming abstraction that represents an immutable collection of objects that can be split across a computing cluster. Operations on the RDDs can also be split across the cluster and executed in a parallel batch process, leading to fast and scalable parallel processing. Much of the Spark Core API is built on this RDD concept, enabling traditional map and reduce functionality, but also providing built-in support for joining data sets, filtering, sampling, and aggregation. Spark SQL is focused on the processing of structured data, using a dataframe approach borrowed from R and Python (in Pandas). But as the name suggests, Spark SQL also provides a SQL interface for querying data, bringing the power of Apache Spark to analysts as well as developers by letting users write join queries across multiple datasets.
Spark Streaming extended the Apache Spark concept of batch processing into streaming by breaking the stream down into a continuous series of micro-batches, which could then be manipulated using the Apache Spark API by using RDDs or converting them to DataFrames. A criticism of the Spark Streaming approach is that micro-batching, in scenarios where a low-latency response to incoming data is required, may not be able to match the performance of other streaming-capable frameworks like Apache Storm, Apache Flink all of which use a pure streaming method rather than micro-batches. Spark’s core design is for aggregation, and micro-batching fitted right into it. If the use case is to process an event without relating it to other incoming events like order management then Storm or Flink will be a better choice. But if you need to correlate IOT data coming from edge devices over a period of time, the sliding windows concept provided by Spark is the most optimal framework. See my notes on it HERE and https://www.linkedin.com/pulse/micro-batching-vs-streaming-amit-tomar/
Structured Streaming
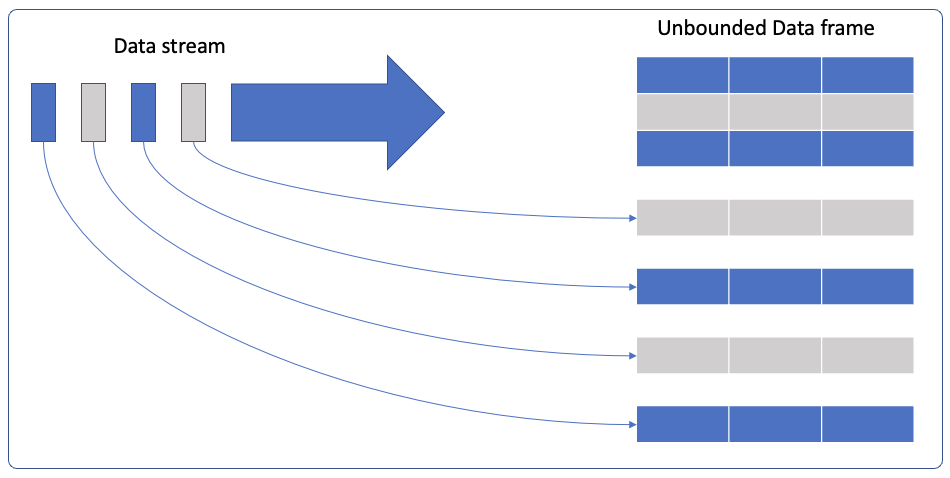
Which brings us to the new near realtime API which essentially allows developers to create infinite streaming dataframes and datasets which allows users to express the same streaming query as a batch query, the code is no different if a DataFrame was on static data or is now on streaming data. However, in streaming case, the aggregation will be continuously updated as new events arrive.
In this example we will use netcat to send sentences to a port where Spark is listening, Spark will split the sentences sent into alphabets, and print a count of each character
import org.apache.spark.sql.functions.
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkAlphabetCount")
.getOrCreate()
import spark.implicits._
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val characters = lines.as[String].map(toCharArray)
// Generate running char count
val charCounts = characters.groupBy("value").count()
// Start running the query that prints the running counts to the console
val query = charCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()To Start sending data to Spark, open a netcat session on terminal using
$ nc -lk 9999Then as you type into the terminal window, with each line a new batch gets evaluated
Lets say we send two inputs
$ nc -lk 9999
ab
acThe output will be
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
| a | 1|
| b | 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
| a | 2|
| b | 1|
| c | 1|
+------+-----+We have not applied any time window to the results yet, so the counts will keep adding up from the start.
Time Windows
There are multiple windowing options for the event stream
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. An input can only be bound to a single window.

val characters = lines.as[String].map(currentTime(), toCharArray)
// DataFrame of schema { timestamp: Timestamp, character: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = characters
.groupBy(
window($"timestamp", "5 minutes"),
$"character")
.count()Sliding windows are similar to the tumbling windows from the point of being “fixed-sized”, but windows can overlap if the duration of slide is smaller than the duration of window, and in this case an input can be bound to the multiple windows.

// Group the data by window and word and compute the count of each group
val windowedCounts = characters
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"character")
.count()Watermarking
In cases when we want to aggregate based on time of event creation instead of the time the event was received by Spark, we need to introduce watermarking which lets the engine track the current event time in the data and attempt to clean up old state accordingly. It also needs to know when an old aggregate can be dropped from the in-memory state because the application is not going to receive late data for that aggregate any more.
In that case the timestamp field is supposed to be passed from input data rather than appending it at event receive time
//The withWatermark () call ensures to account for events delayed upto 10 mins here.
val windowedCounts = characters
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"character")
.count()
Cheers – Amit Tomar


