One of the questions when planning out your data architecture is the question of batch vs stream processing: do you process data in real time or near-real time, or do you wait for data to accumulate before running your ETL job? With so much data moving through your data pipelines, your teams have a series of options to choose from when managing the frequency of their data processing.
Streaming
In stream processing, we process data as soon as it arrives on the message bus or in storage. When the latency needs to be below a second, and data is coming continuously or the response/action is expected immediately real-time data processing is the right kind of data processing to choose.

The following use-cases make good use of real-time data processing:
- Online shopping to start immediate order processing, credit card charge.
- Online trading where security trades and quick investments are made.
- Fraud detection where anomalous activity needs to be recognized and responded to immediately.
- Infrastructure monitoring where issues needs to be quickly picked up.
In case of stream processing, each and every event is always equally important and no message can be ignored or not saved.
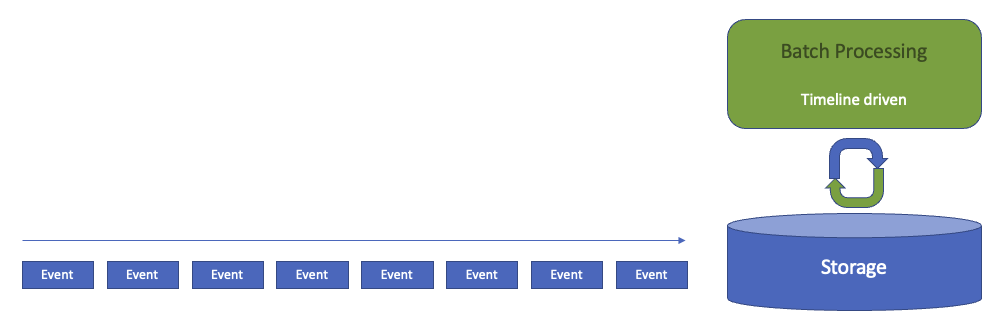
Batch processing
In batch processing, we wait for a certain amount of raw data to “pile up” or a wait for a certain time period before running an ETL job. Typically this means data is between an hour to a few days old before it is processed. Batch ETL jobs will typically be run on a set time (e.g. every 24 hours), or in some cases once the amount of data reaches a certain threshold.
By definition, batch processing entails latency between the time data appears in the storage layer and the time it is available in analytics or reporting tools. However, this is not necessarily a major issue, and we might choose to accept these latency because we prefer working with batch processing frameworks, or it is imposed on us by other external subsystems.
We should lean towards batch processing when:
- Data freshness is not a mission-critical issue
- The processing needs access to the entire batch – e.g., sorting the entire dataset
- You have an external dependency which is batched in nature
- Save costs if a batch job can run on a spot instance on AWS
Micro-batching
In micro-batch processing, we run batch processes on much smaller accumulations of data – typically less than a minute’s worth of data. This means data is available in near real-time. In practice, there is little difference between micro-batching and stream processing, and the terms would often be used interchangeably in data architecture descriptions and software platform descriptions.
A micro-batch may process data based on some frequency – for example, you could load all new data every two minutes (or two seconds, depending on the processing horsepower available). Or a micro-batch may process data based on some event flag or trigger (the data is greater than 2 megabytes or contains more than a dozen pieces of data, for example).

Microbatch processing is useful when we need very fresh data, but not necessarily real-time – meaning we can’t wait an hour or a day for a batch processing to run, but we also don’t need to know what happened in the last few seconds.
It is preferably used in data aggregation use-cases where individual elements of data have significance only at an aggregated level like a mean, min, max over a period of time and instead of writing the logic of fixed or sliding time windows ourselves, we can rely on preaggregated data supplied by micro-batching and discard raw data after processing.
Micro batching is used when:
- Immediate response for each input is not needed
- Individual input elements may not be significant on their own and do not require to be processed beyond aggregation
- A delay of couple of minutes to downstream systems is not critical if we can reduce processing costs.