The message or event is sent from one system to the other system for further processing. There can be multiple producers and multiple listeners. How the message is sent, carried and consumed depends on business usecase.
There are various design factors in messaging technologies which handle robustness and scalability of messaging
There are 2 primary types of messaging patterns
- Publish-subscribe pattern
- Producer-consumer pattern
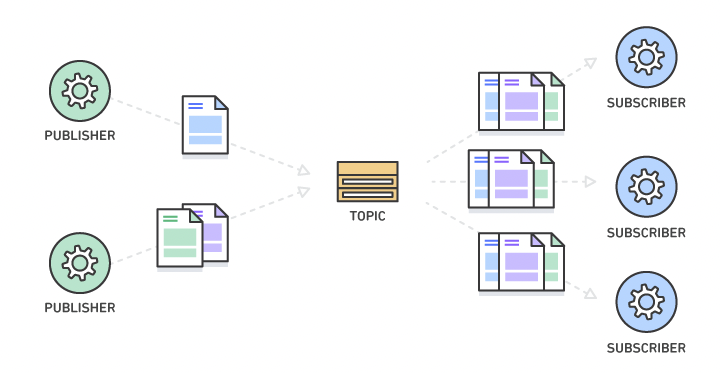
Publish-subscribe pattern
Senders of messages are called publishers. This pattern involves the publisher and the subscriber relying on a message broker that relays messages from the publisher to the subscribers. The host (publisher) publishes messages (events) to a channel that subscribers can then sign up to.The key to this is the fact Pub/Sub enables the movement of messages between different components of the system without the components being aware of each other’s identity.
This is different from the standard request/response (pull) models in which publishers check if new data has become available. This makes the pub/sub method the most suitable framework for streaming data in real-time.
This acts like a one-to-many model where multiple listeners can process the same message in different ways. A event may trigger a email, a text message and a push notification. All these listeners are listening to the same topic for an event to happen and will do all processing in parallel.
One important point in publish subscribe model is that the consumer only consumes the messages generated from the time it starts up. Old messages are ignored. Whichever consumer is present at the time of message arrival, get the message and the message is deleted. If no consumers available then the message is lost.
Also All the consumers are (supposed to be) processing the messages in different ways.
Producer-Consumer pattern
Also known as message queue which is simply a queue where 1 consumer is picking up the data which is pushed in by any producer. We can have multiple consumers of same type in a multi processor environment for scalability but all consumers are controlled by a daemon to avoid reprocessing of same message.
There are 2 primary methods of picking up data from queue
- First in first out
- Random
Here the message stays in the queue till it is picked up by a consumer, or expires.
First in first out guarantees the time order, but blocks the processing of the next event till previous event is processed.
If an event takes lot of time to process, or is constantly failing, this may block the entire queue. So there are ways to have max re-tries, dead letter queues to unblock the processing
There are 2 main ways (guarantees) to do the processing in case multiple consumers are listening to the queue
- At least once
- Once and only once
This is mainly decided by the design of consuming app, there is no correct or wrong way here, but once designed, all enhancements should consider the pre-defined behavior of the queue
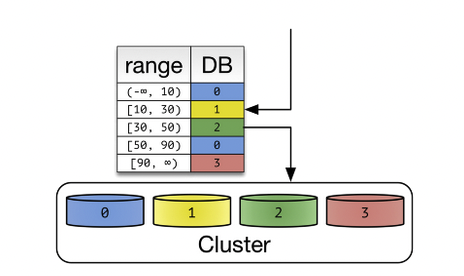
Sharding
Sharding is a method of splitting and storing a single logical dataset in multiple datasets. By distributing the data among multiple machines, a cluster of systems can process larger dataset and handle additional requests. Sharding is necessary if a dataset is too large to be processes in a single machine
Shard or Partition Key is a portion of primary key which determines how data should be distributed. A partition key allows you to retrieve and modify data efficiently by routing operations
Round robin – a message is sent to the next shard in a circular manner. All consumers should be able to process all messages coming in.
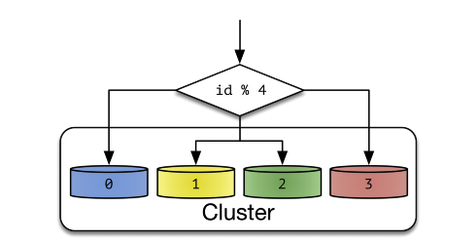
Filter based – a filter on key defines which shard the message will land in. So we can have one particular message type land on a specific shard. This may create a hot spot on a shard if all messages matching a particular criteria land at the same time.